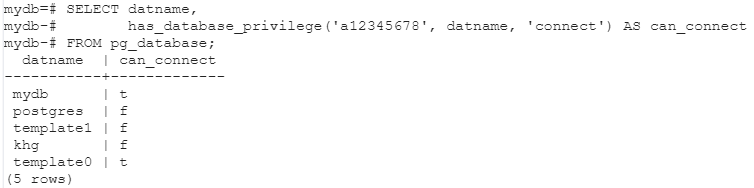
PostgreSQL에서 Index Only Scan은 heap을 읽지 않고 index만으로 결과를 반환하는 고성능 기법입니다.
그런데 shared_buffers 기준으로 실제로 얼마나 I/O가 발생하는지는 잘 알려져 있지 않습니다.이 글에서는 다음 가정 하에 Index Only Scan이 정말 효율적으로 작동하는지,
그리고 shared buffer에서 몇 개의 logical read가 발생하는지 실험을 통해 확인해봅니다.
OS환경 : Rocky Linux 8.10 (64bit)
DB 환경 : PostgreSQL 17.4
✔ 실험 가정
- PostgreSQL 17 기준
- B-Tree 인덱스 사용 (Root → Branch → Leaf 구조)
- 리프 노드 하나에 5개 row 저장됨
- visibility map 최신화 완료 (VACUUM 수행)
- shared buffer에 모든 블록이 올라와 있음
- VM block은 제외
- %d% 검색조건으로 Index Only Scan 유도
- planner 힌트: SET enable_seqscan = off;
✔ 실험 목표
SELECT c1 FROM t WHERE c1 LIKE '%d%';
✔ 실험 스크립트
-- 테이블 초기화
DROP TABLE IF EXISTS t;
CREATE TABLE t (c1 TEXT);
-- 인덱스 생성
CREATE INDEX idx_t_c1 ON t(c1);
-- 데이터 삽입 (한 leaf block에 들어가게 유도)
INSERT INTO t
SELECT 'ad' || i
FROM generate_series(1, 5) AS i;
-- 데이터 확인
select * from t;
c1
-----
ad1
ad2
ad3
ad4
ad5
(5 rows)
-- vacuum으로 VM 최신화
VACUUM t;
-- 실행계획 보려면 Sequential Scan방지
SET enable_seqscan = off;
-- Index Only Scan 실행
EXPLAIN (ANALYZE, BUFFERS)
SELECT c1 FROM t WHERE c1 LIKE '%d%';✔ 실행 결과 (예상&결과)
-- 예상
Index Only Scan using idx_t_c1 on t
Heap Fetches: 0
Buffers: shared hit=3
-- 결과
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Index Only Scan using idx_t_c1 on t (cost=0.13..8.22 rows=5 width=32) (actual time=0.017..0.019 rows=5 loops=1)
Filter: (c1 ~~ '%d%'::text)
Heap Fetches: 0
Buffers: shared hit=2
Planning:
Buffers: shared hit=57
Planning Time: 0.348 ms
Execution Time: 0.056 ms
(8 rows)
🤔 원인 분석
Root → Leaf 바로 연결되는 depth 2 (level 1) 구조
-- 원인
SELECT * FROM bt_metap('idx_t_c1');
magic | version | root | level | fastroot | fastlevel | last_cleanup_num_delpages | last_cleanup_num_tuples | allequalimage
--------+---------+------+-------+----------+-----------+---------------------------+-------------------------+---------------
340322 | 4 | 1 | 0 | 1 | 0 | 0 | -1 | t
(1 row)
💡 해결 방법 (Branch도 보이게 하기)
-- 데이터 대량 삽입 (리프 페이지 증가 → depth 증가 유도)
INSERT INTO t
SELECT 'ad' || i
FROM generate_series(6 300000) AS i(i);
-- VACUUM으로 VM 최신화
VACUUM t;
-- depth 확인
SELECT * FROM bt_metap('idx_t_c1');
magic | version | root | level | fastroot | fastlevel | last_cleanup_num_delpages | last_cleanup_num_tuples | allequalimage
--------+---------+------+-------+----------+-----------+---------------------------+-------------------------+---------------
340322 | 4 | 376 | 2 | 376 | 2 | 0 | -1 | t
(1 row)
EXPLAIN (ANALYZE, BUFFERS)
SELECT c1 FROM t WHERE c1 LIKE '%d%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using idx_t_c1 on t (cost=0.42..11738.42 rows=299970 width=8) (actual time=0.017..35.364 rows=300000 loops=1)
Filter: (c1 ~~ '%d%'::text)
Heap Fetches: 0
Buffers: shared hit=1401 read=212
Planning:
Buffers: shared hit=10
Planning Time: 0.218 ms
Execution Time: 45.477 ms
(8 rows)
✅ 분석 포인트 1: Heap Fetches = 0
✔️ Index Only Scan이 정상 작동 중
✔️ Visibility Map이 최신 상태
→ heap을 보지 않음
→ 완전한 Index Only Scan
✅ 분석 포인트 2: Buffers
| 항목 | 개수 | 의미 |
| shared hit | 1401 | 이미 shared buffer에 올라와 있던 블록에서 읽음 |
| shared read | 212 | 디스크에서 읽은 후 shared buffer에 올림 |
| 합계 | 1613 | 총 logical read 횟수 |
💡 Index Only Scan을 하면서 index block들을 반복적으로 접근
✅ 분석 포인트 3: 왜 300,000 row인데 블록은 1613개만 읽었을까?
이게 PostgreSQL의 구조를 정확히 보여주는 부분이에요:
- PostgreSQL은 row-by-row로 leaf block을 순차 탐색
- 하지만!
B-Tree 경로 상에서 동일한 block이 반복 접근되기 때문에
→ block 수(=relpages)는 적더라도
→ shared hit은 row 수에 비례해 증가할 수 있음
여기선 leaf page 약 1200개 + branch/root 포함 1613개 정도 block을 순회
🎯 결론
실제 Index Only Scan에서 30만 개의 row를 탐색했음에도, 총 logical read는 약 1,600개에 불과했습니다. 이는 PostgreSQL이 leaf block을 한번에 sequential하게 읽는 구조가 아니라, 현재 위치를 유지하며 row-by-row로 순차 탐색하는 iterator 방식이기 때문입니다. 따라서 하나의 branch, root block이 수십만 row에 의해 반복적으로 hit되며, shared hit 수가 relpages보다 훨씬 많이 나올 수 있습니다.
🙌 댓글, 공감, 공유는 큰 힘이 됩니다! 😄
참조 : https://www.postgresql.org/docs/current/indexes-index-only-scans.html
'RDBMS > PostgreSQL, EDB' 카테고리의 다른 글
| [PostgreSQL] PostgreSQL은 RBO? CBO? 과연 어떤 방식을 채택할까? (0) | 2025.04.22 |
|---|---|
| [PostgreSQL] Block Corruption 해결 방법 (TABLE, INDEX) (0) | 2025.04.22 |
| [PostgreSQL] Oracle과 다른 Index Only Scan 구조와 그 이외 궁금증... (0) | 2025.04.07 |
| [PostgreSQL] Password(패스워드) 만료, 테이블 권한 부여, 권한 분리 설정 (0) | 2025.03.31 |
| [PostgreSQL] 아키텍처(Architecture) 별 관련 파라미터 (0) | 2025.03.13 |